技术 SEO 必备技能:网站日志分析

在技术 SEO 的众多能力中,网站日志分析(Log Analysis)常常被忽视,但它却是能让SEOer们研究搜索引擎抓取、收录的利器,通过网站日志可以清晰得看到搜索引擎到底做了什么。下面一文带你学会“如何进行网站日志分析”。
什么是网站日志?为什么对 SEO 如此重要?
网站日志(Server Log)是服务器自动生成的访问记录,相当于网站的“访问黑盒”,会详细记录每一次外部请求的关键信息,核心字段包括:
- 访问时间:精确到秒,可追溯爬虫访问时段规律
- 访问 IP:爬虫或访客的真实 IP 地址(可用于验证爬虫真实性)
- 请求的 URL:被访问的具体页面路径
- 请求状态码(200 / 301 / 404 / 500 等):请求是否成功、页面是否存在等
- User-Agent(UA):访问者身份标识(核心用于识别搜索引擎爬虫)
对于 SEO 而言,日志的核心价值在于“直接还原搜索引擎爬虫的访问行为”——第三方工具只能给你“推测数据”,而日志能给你“真实轨迹”。
通过日志,你能明确知道:
- Googlebot / Bingbot / Baiduspider 等是否真的访问了你的核心页面
- 哪些页面被频繁抓取(如首页、核心分类页),哪些页面几乎无爬虫问津(如深层商品页、过期活动页)
- 爬虫是否把“抓取预算”浪费在无价值页面(如参数页、重复内容页、搜索结果页)
- 404(页面不存在)、500(服务器错误)等报错页面是否仍被爬虫持续抓取,造成预算浪费
这些信息,第三方工具(如 Ahrefs、Semrush)无法完整获取,只能通过日志精准定位。
日志分析能让我们做哪些 SEO 优化?
1. 让搜索引擎抓取更加高效
大型网站(尤其是电商、资讯站)最容易出现的问题:搜索引擎把大量抓取资源花在“垃圾页面”上,导致核心页面(如转化页、新品页)抓取频率不足。通过日志分析,我们可以看到搜索引擎大量抓取的是不是核心页面,如果不是,可以通过调整robots.txt和设置301让爬虫去抓取核心页面。
通过日志可精准识别以下场景:
- 场景1:参数页被大量抓取 ,如电商站 :
/product?id=123&sort=price&page=2- 判断命令(Linux 环境):
grep "Baiduspider" access.log | grep "?sort=" | wc -l(统计百度爬虫抓取参数页的次数) - 解决方案:在 robots.txt 中屏蔽参数规则,示例:
Disallow: /*?sort= Disallow: /*&page=同时给参数页设置 canonical 指向主页面。
- 判断命令(Linux 环境):
- 场景2:已下线/设置 noindex 的页面仍被抓取 (如过期活动页 '/2023-double11')
- 判断方法:日志中筛选该 URL + 爬虫 UA,若存在持续访问记录,说明爬虫未识别 noindex 或未同步下线状态。
- 解决方案:给该页面设置 301 跳转至相关活跃页面。
- 场景3:重复 URL 消耗抓取预算 (如 '/product/123'和'/product/123/'尾部多斜杠)
- 判断命令:
grep "Googlebot" access.log | grep "/product/" | sort | uniq -c | sort -nr(统计谷歌爬虫抓取的商品页 URL,看是否有重复形式) - 解决方案:修改列表页,统一url。
- 判断命令:
2. 让新页面被及时发现(内容站/电商站重点)
很多时候新页面(如新闻稿、电商新品页)迟迟不收录,不是内容质量问题,而是爬虫根本没访问过——这时候日志就是“诊断利器”。
实操判断步骤(以百度爬虫为例):
- 筛选新页面日志:
grep "Baiduspider" access.log | grep "/new-product/20260104" - 查看结果:① 无结果 → 爬虫未发现该页面;② 有结果但仅 1 条 → 仅被发现一次,未持续抓取;③ 每天有多次记录 → 抓取正常。
- 抓取延迟判断:对比页面发布时间(如 2026-01-04 10:00)和日志中首次抓取时间(如 2026-01-05 08:30),计算延迟时长(约 22 小时)。
解决方案:
- 若爬虫未发现,可通过 sitemap 提交(百度站长平台 → 数据提交 → sitemap)、内链引导(在首页/分类页添加新页面链接);
- 若抓取延迟过长,可通过百度站长平台“手动抓取”功能触发爬虫访问。
3. 排查隐藏的技术错误
很多技术错误(如间歇性 500 错误、过长跳转链)在页面抽样检查中难以发现,但在日志中会“暴露无遗”,这些错误会直接影响爬虫抓取和页面权重传递。
核心排查场景:
- 场景1: 404/500 错误
- 排查命令(统计百度爬虫访问的 404/500 页面及次数):
grep "Baiduspider" access.log | grep -E " 404 | 500 " | awk '{print $7}' | sort | uniq -c | sort -nr - 解决方案:
- 404 页面 → 检查是否为死链,设置 301 跳转或提交死链;
- 500 页面 → 联系服务器运维排查,可能是程序报错或服务器负载过高。
- 排查命令(统计百度爬虫访问的 404/500 页面及次数):
- 场景2:301/302 跳转链过长(超过 3 次跳转)
- 排查方法:日志中筛选跳转状态码(301/302),跟踪 URL 跳转链(如
A → B → C → 目标页),过长跳转会导致爬虫放弃抓取,权重传递损耗。 - 解决方案:简化跳转链,直接让 A 跳转至目标页。
- 排查方法:日志中筛选跳转状态码(301/302),跟踪 URL 跳转链(如
- 场景3:CDN 间歇性返回异常状态码(如 502 Bad Gateway**)**
- 排查方法:对比服务器日志和 CDN 日志(如 Cloudflare 日志),若 CDN 日志中出现大量 502,而服务器日志正常,说明 CDN 节点故障。
- 解决方案:联系 CDN 服务商切换节点,或临时关闭 CDN 测试。
4. 检查搜索引擎是否理解站点结构(信息架构优化关键)
你在 sitemap、内链、导航中重点突出的核心页面(如首页、核心分类页),是否真的被爬虫“重视”?日志能直接验证你的站点结构是否对搜索引擎友好——核心判断标准是“爬虫抓取频率与页面权重是否匹配”。
对比方法:
- 对比内链权重与抓取频率:内链最多的页面(如首页,内链数 1000+)应是抓取频率最高的;若内链多的分类页抓取频率低于内链少的参数页,说明站点结构有问题。
- 排查命令(查看谷歌爬虫抓取Top20的页面,判断是否为核心页):
grep "Googlebot" access.log | awk '{print $7}' | sort | uniq -c | sort -nr | head -20
- 排查命令(查看谷歌爬虫抓取Top20的页面,判断是否为核心页):
- 分析深层页面抓取情况:以“首页→分类页→子分类页→商品页”的4级结构为例,若3-4级商品页几乎无爬虫访问(日志中无记录),说明站点结构过深,爬虫无法触达。
- 检查目录抓取分布:通过命令
grep "Baiduspider" access.log | awk '{print $7}' | cut -d'/' -f2 | sort | uniq -c | sort -nr统计各目录的抓取次数,若核心目录(如 /product)抓取次数低于非核心目录(如 /news),需调整内链和导航权重。 - 案例:某电商站日志显示,3级商品页 '/category/phone/iphone/123'每周抓取次数仅 1-2 次,而 2 级分类页'/category/phone' 每天抓取 10+ 次——解决方案:在分类页添加该商品页的内链,或在 sitemap 中单独列出核心商品页。
网站日志在哪?
说了那么多,网址日志在哪?应该怎么找到它?当然有两种方式:1、如果有专人负责运维的话,那么找技术同学要。2、如果是个人站长的话,可以参考下面路径获取日志:
自己获取日志
- Nginx 日志:默认路径 /usr/local/nginx/logs/access.log;若配置过自定义路径,可查看 nginx 配置文件(/usr/local/nginx/conf/nginx.conf)中的 access_log 字段。
- Apache 日志:默认路径 /var/log/apache2/access.log(Ubuntu)、/var/log/httpd/access_log(CentOS)。
- CDN 日志:Cloudflare(控制台 → 日志 → 启用“日志推送”,可导出至 S3 或本地);Akamai(控制台 → 报表 → 日志管理,筛选“访问日志”导出)。
如何识别蜘蛛
常见真实爬虫 UA** (精准匹配用)**:
- Baiduspider(百度):
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Googlebot(谷歌):
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Bingbot(必应):
Mozilla/5.0 (compatible; Bingbot/2.0; +http://www.bing.com/bingbot.htm)
筛选命令(Linux 环境):
- 筛选百度爬虫:
grep "Baiduspider" access.log > baiduspider_log.log - 筛选谷歌+百度爬虫:
grep -E "Googlebot|Baiduspider" access.log > seo_crawler_log.log
验证爬虫真实性**(避免伪造 UA 干扰)**:
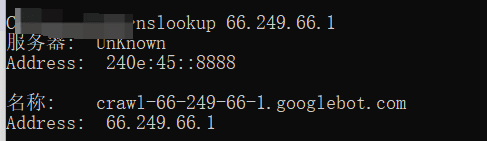
部分恶意爬虫会伪造 UA 冒充搜索引擎,需通过 IP 反向解析验证,示例(验证 Googlebot IP 66.249.66.1):使用命令行(windows下:win+r,输入cmd):nslookup 66.249.66.1 → 若返回结果包含 crawl-66-249-66-1.googlebot.com,则为真实爬虫;无返回则为伪造。
第三方工具进行日志分析
使用命令行的方式进行日志分析,终究是多慢,命令行也难记下来,每次分析都得翻笔记。使用第三方工具也可以实现同样的效果
步骤:使用FTP将网站日志下载到本地,安装第三方工具或使用在线版本打开网站即可进行分析。
第三方分析工具:爱站SEO工具包(客户端)、爱站网站日志分析(在线版)